Building Reliable Agentic Systems: Lessons from the Front Lines of Data Engineering, by Julian Wiffen, Chief of AI and Data Science – Matillion
Julian’s talk, “Building Reliable Agentic Systems: Lessons from the Front Lines of Data Engineering,” presents a practical, experience-driven view of how agentic AI is transforming data engineering in real enterprise environments. Rather than focusing on future possibilities, he emphasizes that most of the discussed capabilities are already live in production, used by large organizations.
He begins by framing the core problem: enterprises are eager to adopt AI, but progress is often blocked by poor data readiness. Data is fragmented across legacy systems, inconsistent formats, and complex pipelines. Historically, data teams have spent most of their time maintaining infrastructure rather than generating insights. The rise of generative AI intensifies this challenge by dramatically increasing both the volume and variety of data—especially unstructured formats like text, audio, and video—while also increasing demand for high-quality data to power AI systems.
To address this, Julian introduces an “agentic AI data engineer,” a system designed to automate data engineering tasks. This system uses large language models (LLMs) combined with tools that allow it to explore, transform, and validate data. Users interact with it through natural language, delegating tasks rather than manually coding solutions. The agent operates in a loop: planning actions, exploring data, building pipelines, validating outputs, and iterating based on feedback. This mirrors how a human engineer works but executes far faster.
A key principle is “thinking inside the box”—constraining LLM outputs to structured, testable formats. By limiting choices (e.g., multiple choice, yes/no outputs, or predefined components), the system becomes more reliable and easier to validate. This constraint enables automated testing and reduces the risk of errors, especially in complex workflows.
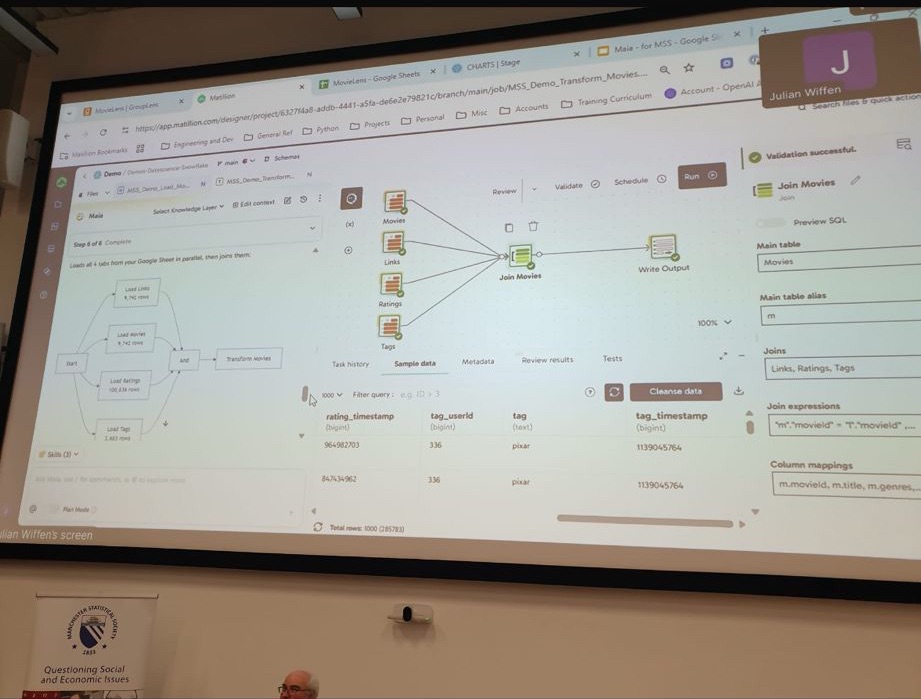
Julian demonstrates how the system can ingest data, explore schemas, join tables, clean inconsistencies, and generate analytical outputs—all while allowing user oversight. The human role shifts from hands-on execution to task delegation and validation, similar to managing a junior team member. Importantly, the system provides transparency through visual pipelines, making it easier to inspect and trust results.
Testing such non-deterministic systems requires new approaches. Julian describes a three-model evaluation framework: one model performs tasks, another acts as a tester, and a third judges results against expected outcomes. By running scenarios multiple times, the team measures consistency. Failures are analysed using embeddings and clustering to identify common error patterns. Constraining outputs into structured formats (like multiple choice) further enables scalable evaluation using traditional metrics.
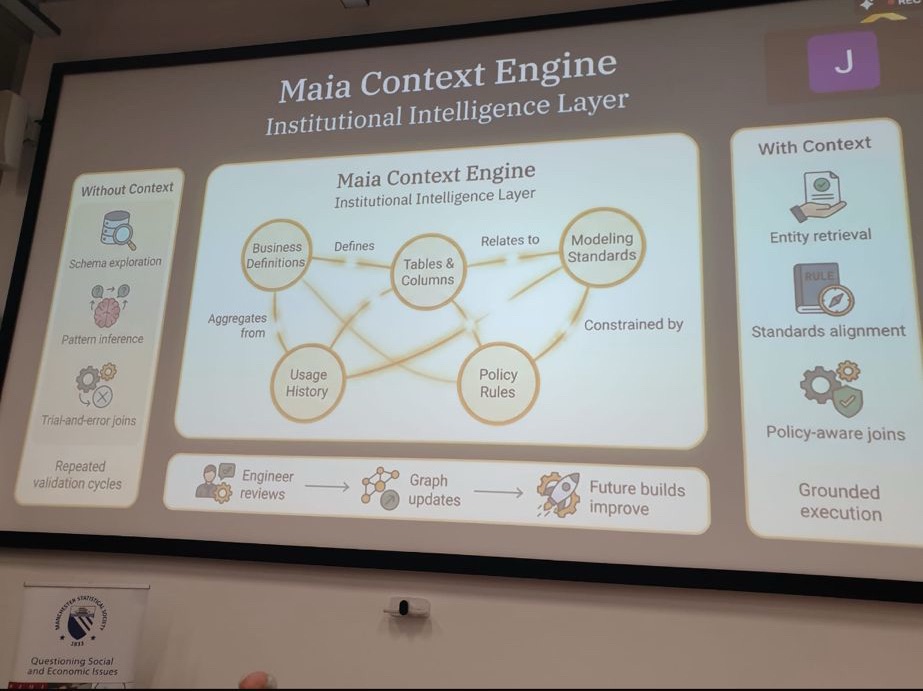
Another major theme is the importance of context. Beyond executing tasks, the system must understand business meaning—such as which “sales” table is relevant among thousands. To solve this, Julian describes building knowledge graphs from metadata, documentation, usage patterns, and user interactions. These graphs help the system map entities, relationships, and meanings, improving accuracy and relevance. Context also includes understanding differences in terminology across teams, such as finance versus sales definitions.
Julian highlights additional use cases, such as converting unstructured data into structured insights using simple classification tasks (“yes/no” questions). This enables powerful applications like analysing surveys, transcripts, or patient diaries. The approach allows organizations to revisit historical data with new questions, unlocking additional value without recollecting data.
From a team perspective, AI does not replace roles but elevates them. Tasks shift down the skill ladder: senior engineers handle more complex work, while junior engineers and even non-technical users can perform tasks that previously required expertise. Productivity increases dramatically, similar to how calculators enhanced engineers without replacing them. The overall effect is faster execution and greater scale.
On security, Julian notes that risks depend on how models are deployed. Enterprise-grade setups that avoid training on customer data are comparable to standard cloud services. Proper controls—such as secure hosting and secrets management—are essential.
Finally, he reflects on organizational lessons: success comes from experimentation, strong documentation, diverse teams, and close collaboration between data science and engineering. Internal use (“dogfooding”) and implicit feedback (like user behaviour) are more valuable than explicit ratings. His overarching advice is to experiment continuously, as rapid advancements in AI mean that partially working solutions today can become highly effective in a short time.
Overall, the talk presents a grounded, systems-focused view of agentic AI as a powerful tool for scaling data engineering, improving reliability, and reshaping how teams work.